Bandwidth Struggles and Premature Optimization
I’ve been supporting a scripting framework for a MUD for several years and part of the infrastructure is maintained on Firebase using a free tier plan. I became inured to the monthly e-mails reminding me that I was at 90% of my data limit showing up on the 30th 29th 28th… shit.
Punished By Success
It was probably inevitable that we would reach this point, adoption of our project had been growing steadily and user behavior was changing in ways that increased their data demands. I wasn’t going to start giving Google nickles of my money each month without a fight so I prepared to spend hours of my time on a solution. To provide more context I will first answer the pressing question, why does a MUD script repository need a database?
We store two pieces of data in our database, The first is a crowd sourced collection of data about in game tasks that can shift over time. This data is accessed by clients only when it has changed, so is not our culprit for the bandwidth issue. The second set of data is today’s troublemaker. A fair part of the magic and transportation for the MUD in question is dependent on time. In game terms the location of the sun and the planet’s three moons. The state of these bodies is not deterministic for the players of the game. That is until someone tracks months worth of data and finds the cycle that they operate on. Lacking that determinism we can make approximations that are accurate within 5~ minutes. These calculations are based on in game observations by the one class capable of accurately judging the celestial bodies. This information is useful for the class in question and mildly convenient for everyone else. It takes work to obtain this information in game so we set up an automated system for tracking these events. This allows anyone who is interested to have constant access to the data.
Trusting this data as a player can be risky. If you have the wrong information it can easily result in character death. In a game with the possibility of permanent item loss it’s not something you want to get wrong. I still remember every item players have lost using code I’ve written. We approached the solution for this from a couple directions. Firstly we’d prefer to work with timestamps so local users can tell on their own if their data is out of date instead of blinding trusting an offset value. The next two ideas work in tandem. We set a convention that our script logic wouldn’t take risks. If you were within a minute or so of a transition we’d default to the safer option of the two available. Secondly we’d reach out for an update on the timestamps once a minute to catch any changes immediately.
Back of the envelope math said this shouldn’t be too much of a problem. A highly optimistic 200 users pulling down 350 bytes of data once a minute was only 100MB a day. This leaves us a 2x safety net versus our 10GB monthly limit. Trusting that we did the simplest implementation possible and just let users poll the data each minute. This let us move on to work on other things, and we were correct for several years.
Push It To the Limit
So it’s become obvious that we’d missed something. It wasn’t until I hovered over the bandwidth tooltip in the site console that I realized where we’d gone awry.
Downloads account for all bytes downloaded from your database, including connection protocol and SSL encryption overhead
But how much overhead could those really entail? I didn’t have an easy way to measure it from our metrics nor did we really know how many times users were requesting data (or so I thought at the time). Instead I had a potential solution that was probably faster to implement than it would be to measure out what our communication overhead actually was so I went with that approach.
Everyone who’s worked with web development is familiar with minified files and why we want them. I figured it was time to minify the footprint of our json and I could just apply mappings locally to restore human readable values.

These changes took our data from 350 bytes down to 200. Even if the communication overhead was doubling our data usage we should still see a 10-15% reduction, keeping us under our limit for probably another year of user growth easily. On May 3rd I flipped the switch and patiently waited for the metrics to roll in, and in one week I planned on disabling the old data endpoint entirely.
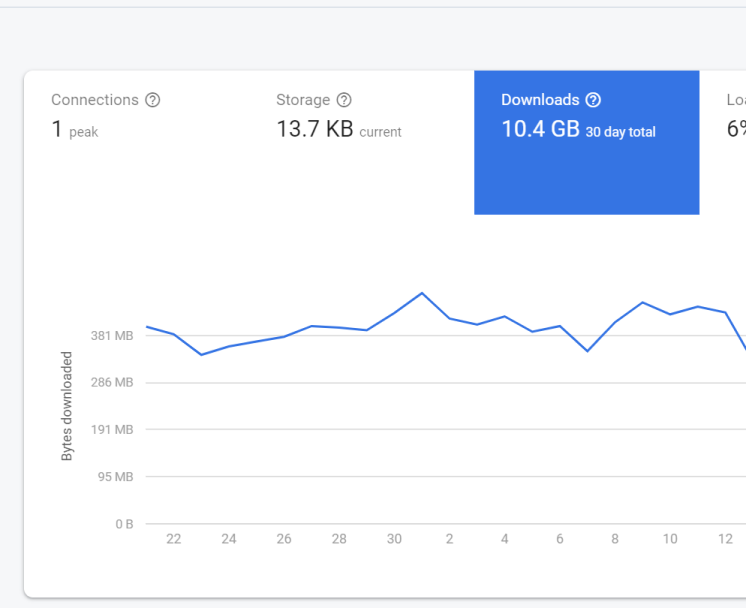
And… no measurable change occurred over the next several days. Perhaps most of our users weren’t on the new codebase? On the 9th I killed the old data endpoint, still nothing. While I didn’t know exactly how bad the communication overhead was; I’d proven that no change to our data format was going to resolve the issue. Instead we needed to be smarter about requesting data.
Well That Was Easy
Perhaps not surprisingly, the correct solution really wasn’t that difficult to implement. We had decent estimates on when the next event should occur, why don’t we trust those estimates a little more? They may be a few minutes off over a 3 hour window, but they’re never going to be an hour off. We changed our code to poll at the greater of either 80% of the time until the next event, or 1 minute. We’d keep the same accuracy, but reduce the number of requests dramatically. On May 16th I made this change and pushed it out to the users.
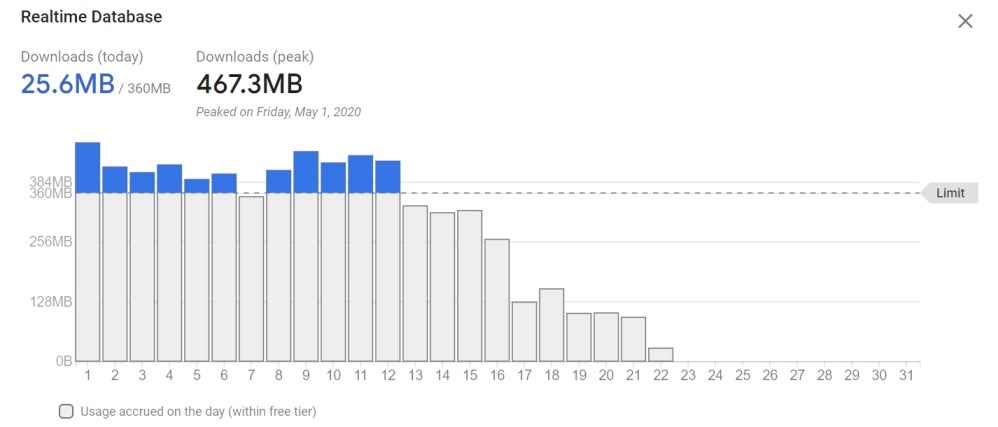
As I was reveling in the huge performance gains I discovered that we could also view a count of every attempted access to our data via the rule monitoring logic.
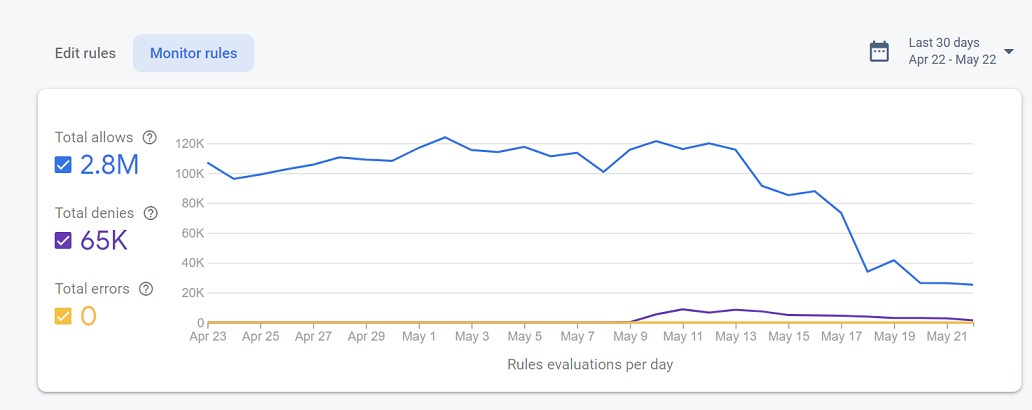
Using these counts it became easy to calculate that our per communication size averaged almost 4KB. It’s not surprising that shaving 150 byte reduction got completely lost in the noise. I also found it interesting to look at the rejection rate. Those denials indicate users running out of date code still trying to access the old data endpoint after it was disabled. If you want to talk about long tails we were still getting about 6k failed communications daily even into October. It wasn’t until October 10th that they all finally stopped, leaving me to believe it was one user running ~3 characters 24/7 who hadn’t updated in over half a year.
Looking back on things I do not regret attempting a simple solution first that could let us course correct if our assumptions were wrong. It’s also arguable that the initial design decision was correct. We had a very large backlog of items to tackle for this project and it took years before this quick solution caused enough pain to be addressed further. Deciding how heavily to invest in optimizations is always a tricky question. You should weigh the expected cost of coming back to code that will be unfamiliar to make further changes against delivering more user value now.